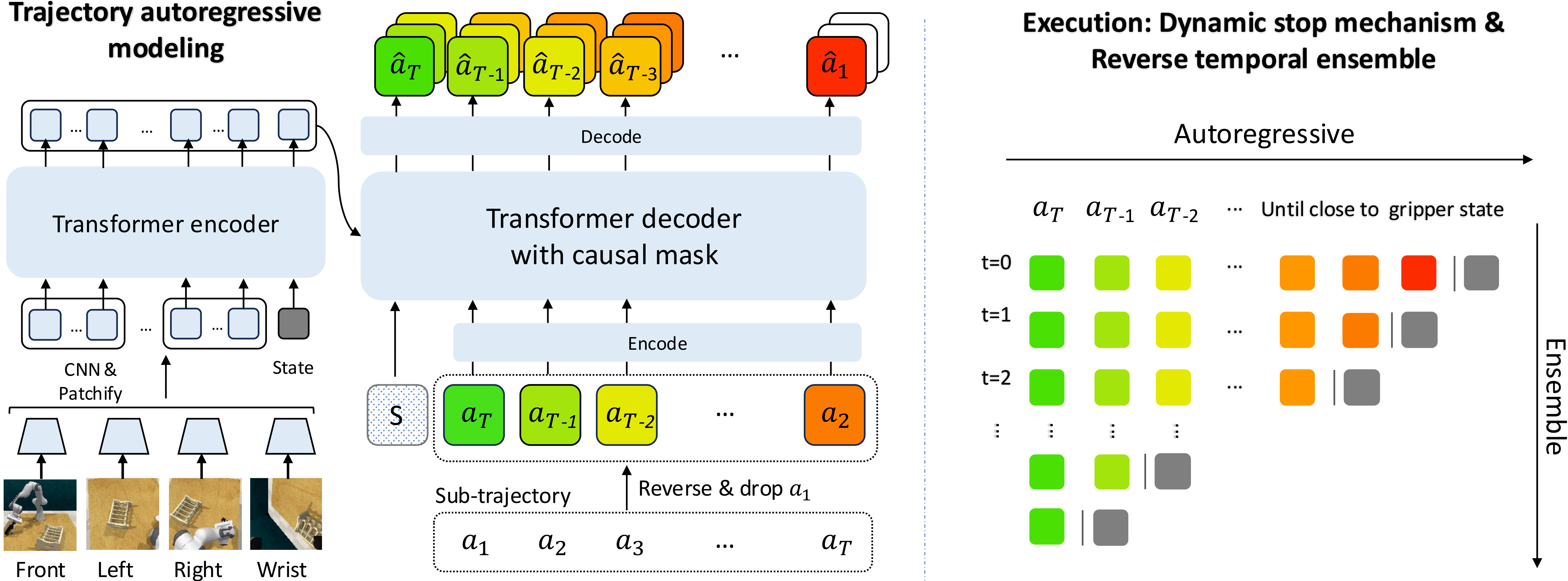
Is the keyframe action (i.e., goal pose) predicted or provided?
Both the keyframe action and subsequent actions are predicted. They are unified within the same action space and generated through autoregressive modeling. The keyframe action is obtained using a learnable start-of-sequence token.
How does CoA differ from traditional methods (such as pose estimation and planning)?
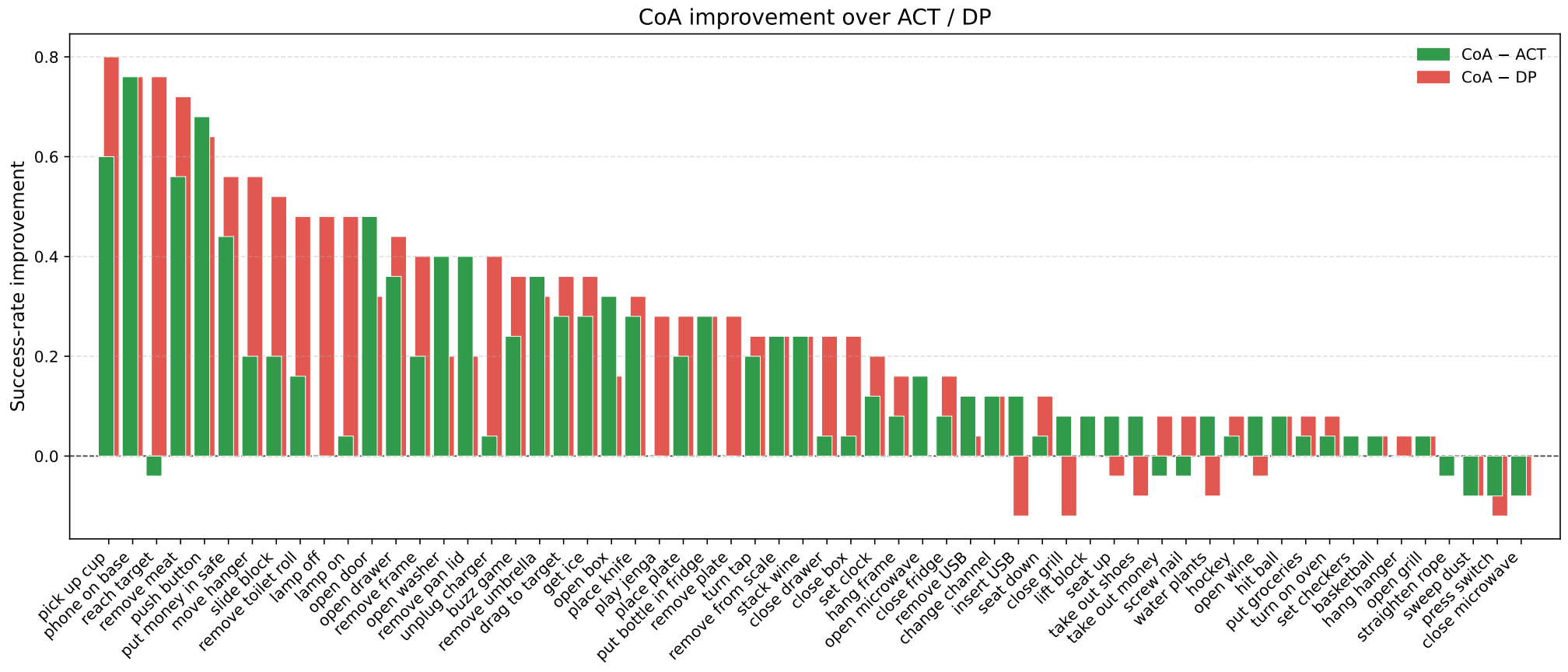
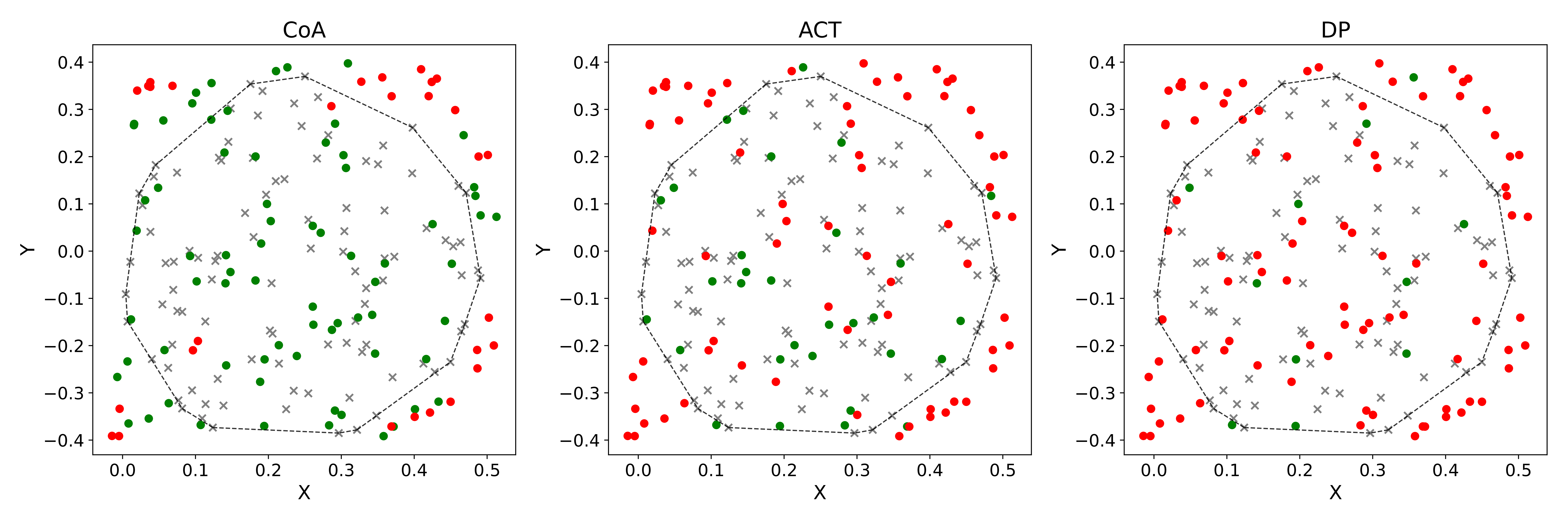
CoA offers greater flexibility and can handle more complex tasks. It is environment-aware, capable of executing actions in a closed-loop manner, and does not depend on high-quality 3D perception. Overall, CoA is a visuomotor policy algorithm that can be compared to ACT and DP.
Have you tried providing the keyframe action to ACT?
Yes, we have experimented with providing the keyframe action to ACT, but the improvement was not significant. Our ablation study showed that both action chain modeling and using the keyframe action as the start of the sequence are necessary.
How do you ensure that the generated actions end at the gripper's starting position?
We design a dynamic stopping mechanism that halts the generation process once the gripper reaches its starting position.